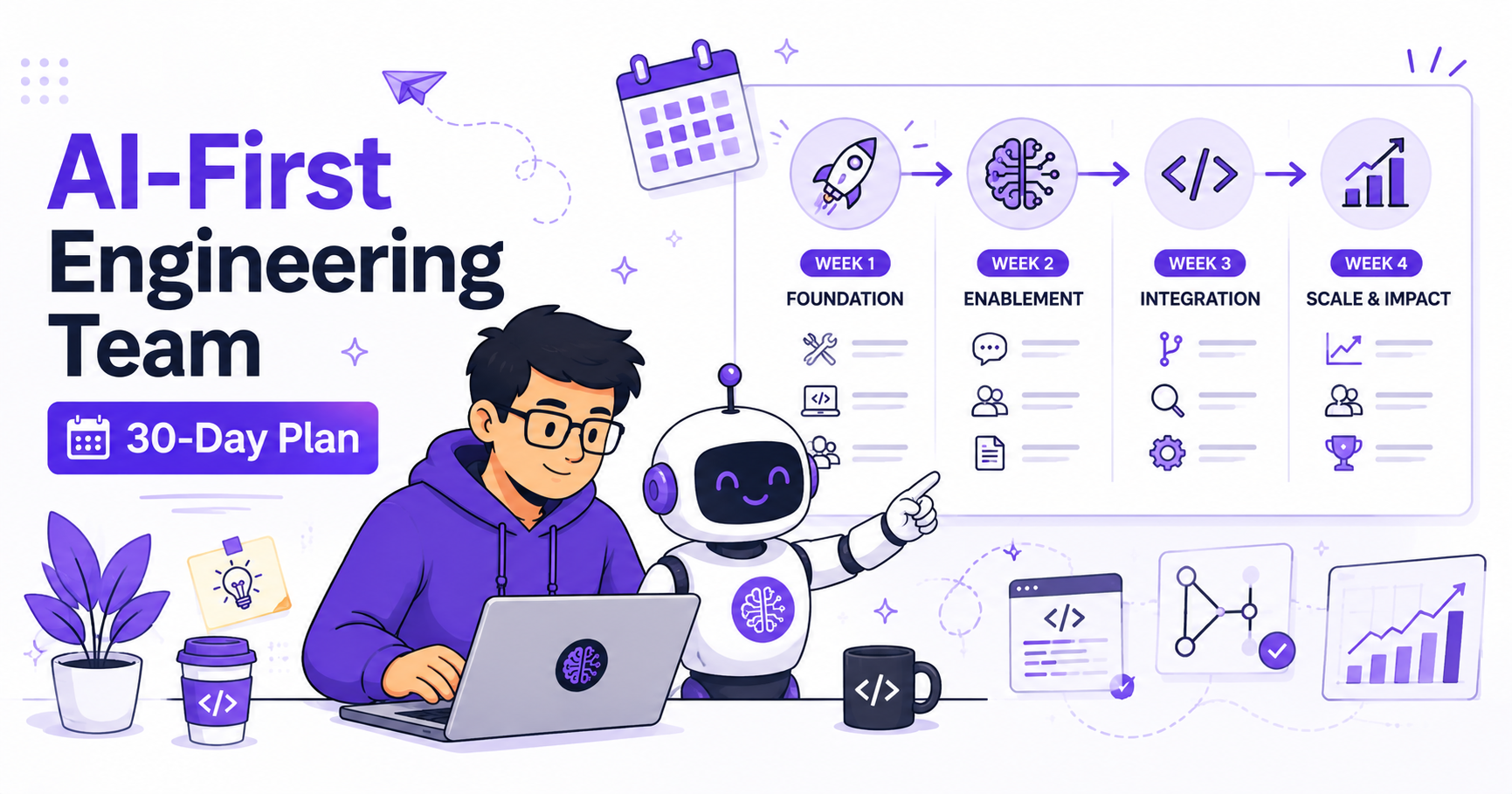
The AI-First Engineering Team — 30-Day Blog
A 30-day series on what changes when an engineering team — not just an individual engineer — adopts AI as a first-class part of how they work. From culture and workflows to governance and the human side.
A 30-day series on what changes when an engineering team — not just an individual engineer — adopts AI as a first-class part of how they work. From culture and workflows to governance and the human side.
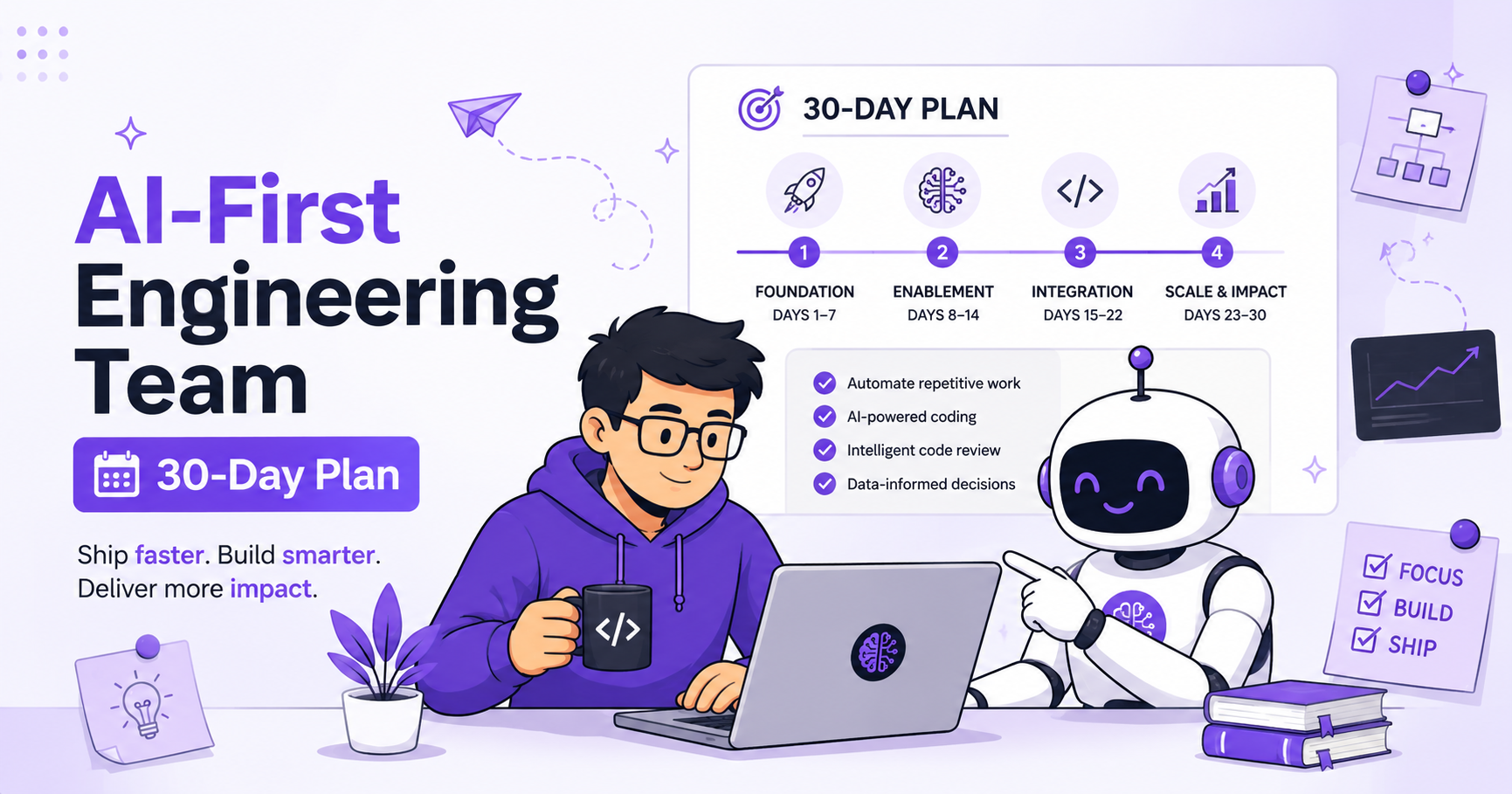
A structured 30-day blog roadmap covering Claude Code, GitHub Copilot, Microsoft Copilot Studio, agentic AI, coding agents, and AI in SDLC — from a Lead AI Engineer with 11 years of experience.
What engineering managers need to own when deploying AI agents — blast radius, rollout strategy, stakeholder expectations, and the first production incident.
How to measure whether AI tools are making engineering teams more productive — and which metrics will mislead you.
Why enterprises are creating dedicated AI platform engineering teams, what they own, and how to staff and measure them.
How to wire Claude Code and GitHub Copilot into a spec-driven workflow — the AGENTS.md pattern, Copilot Workspace integration, and the production SDD pipeline that actually ships.
Rolling out spec-driven development across an engineering organization requires governance structures, change management, and the right sequencing — here is what actually works.
What AI agents can realistically automate in compliance workflows — and where human judgment is still the only acceptable answer.
OpenSpec is an emerging open standard for writing AI-executable specifications — structured enough for agents to implement, human-readable enough for engineers to review.
Traditional SAST tools miss business logic flaws and context-dependent vulnerabilities — here is how to layer AI-assisted scanning on top, including custom security agents and triage automation that actually reduces noise.